
 Xbox Cloud Gaming Equirements: Internet, Devices, Controllers
Xbox Cloud Gaming Equirements: Internet, Devices, Controllers  How to Delete Sent Messages on iPhone From Both Sides
How to Delete Sent Messages on iPhone From Both Sides  Portable Monitor For Laptop Guide
Portable Monitor For Laptop Guide  Optimizing Sales Prospecting with Modern Software Tools
Optimizing Sales Prospecting with Modern Software Tools  What Is One Way That Technology Can Improve The Distribution Of Goods?
What Is One Way That Technology Can Improve The Distribution Of Goods?  Xbox Cloud gaming: A Practical Guide For Real Life
Xbox Cloud gaming: A Practical Guide For Real Life  Game Pass vs PlayStation Plus: which is actually worth it?
Game Pass vs PlayStation Plus: which is actually worth it?  Macfox X1S installation guide: assembly, setup, and first ride checks
Macfox X1S installation guide: assembly, setup, and first ride checks 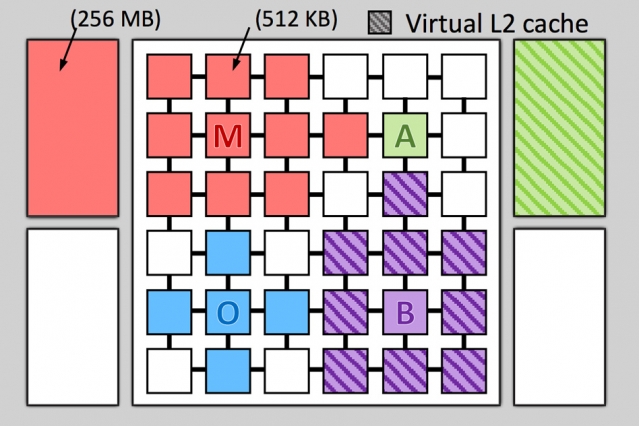
Researchers at the Computer Science and Artificial Intelligence Laboratory at MIT have succeeded in developing a new ad hoc cache splitting method, which increases the computing power by up to 30% with otherwise identical hardware and reduces energy consumption by up to 85%. The combined use of self-organizing communication concepts in combination with classical, hierarchically organized topologies is increasingly the focus of scientific considerations in the field of highly dynamic, wireless network structures. Notwithstanding the fact that hierarchical structures remain indispensable from a certain scaling stage onwards, the partial elimination of central administrative instances into the lower hierarchical levels opens up completely new fields of application.
Mobile Ad Hoc Networks (MANET) and their ability to spontaneously network offer significant advantages over completely centrally organized structures. This results in a more uniform network load distribution, which in turn results in an efficient use of the available energy resources and a robust behavior in comparison to partial faults.
For decades the computing power of processors has been increased by means of so-called caches, bridging the gap between the relatively slow RAM of the working memory and the high process location clock.
A cache is a small, usually on The integrated memory with very high clock frequency, on which the data cores can access almost unbraked. For a long time CPUs for PCs and laptops have even a smaller 1st- and a slightly larger 2nd-Level Cache. The Pentium 4, for example, came with two L1 caches, each with 8 KB and an upstream L2 cache with 256. A current i7, on the other hand, has a separate 32 KB L1 cache for instructions and data as well as an additional L2 cache of 256 KB with a full process port act plus a slightly slower L3 cache of up to 20 MB for all cores , In order to further increase the computing power independently of the cycle, extreme measures are taken which cost a lot of space on the die, and thus are expensive and increase the energy consumption. Keep in mind that a little more than 20 years ago a normal PC had less main memory available than today a CPU L3 cache!
The MIT researchers have now investigated alternative strategies of acceleration. Hardware for the experiments was a Jenga system, with a 36-core CPU with a configurable L3 cache with the enormous size of 1 GB L1 and L2 caches were allocated as usual fixed to the individual cores. The key difference now is that the L3 cache is ad hoc, i. While the code could be adapted to the code needs. Then a thread, which is currently a large array with z. Such as 32 MB space requirement, not just about 1/36 of the L3 cache, but as much as needed. The unnecessary two- or multi-step procedure in the fixed allocation is thus avoided together with the unnecessary data bustle. The result is not only an increase in code execution by 20 to 30%, but also an energy saving of 20 to 85%, since unnecessary internal operations are significantly reduced.